You bought the high-value treats. You watched training videos. You’re consistent. You’re rewarding good behavior immediately. Everything you’re doing matches what you read about positive reinforcement training. Yet your dog still doesn’t listen. They sit perfectly when you’re practicing with a handful of treats, but ignore you at the dog park. They respond half the time. They seem to have selectively decided which commands matter and which ones don’t.
Here’s what most dog owners don’t understand: positive reinforcement training absolutely works. The science is clear. But the gap between “positive reinforcement works in theory” and “positive reinforcement is actually working for YOUR dog” is enormous. Most owners are implementing it incorrectly without realizing it. They’re not failing because positive reinforcement is wrong—they’re failing because they’re missing critical pieces of execution.
At The Mannered Mutt, we see this constantly. Dog owners in The Woodlands and Conroe come to us after months of trying positive reinforcement training on their own. They’re convinced the method doesn’t work, when actually they’ve been making the same six mistakes that sabotage training. Once we diagnose and correct these implementation problems, their dogs transform. The same rewards they were using start working. The dog who “refused to learn” suddenly learns quickly.
This guide exposes what you’re likely missing, helps you diagnose why your positive reinforcement training has stalled, and explains when DIY attempts need professional guidance to succeed.
Why Positive Reinforcement Works (And Why Yours Isn’t)
The science is ironclad. Research from veterinary behavioral medicine confirms that reward-based training produces better obedience, fewer behavior problems, and lower stress in dogs compared to punishment-based methods. Dogs trained with positive reinforcement are more eager to learn, more responsive, and have stronger bonds with their owners.
So if the method works so well, why are thousands of frustrated dog owners in Montgomery County giving up on it?
The answer is simple: positive reinforcement training only works when implemented correctly—and correct implementation is harder than most people think. Understanding the principle (“reward good behavior”) is easy. Executing it flawlessly takes skill, timing, consistency, and diagnostic ability. Most owners are missing at least one critical piece.
The 6 Mistakes Most Dog Owners Make with Positive Reinforcement
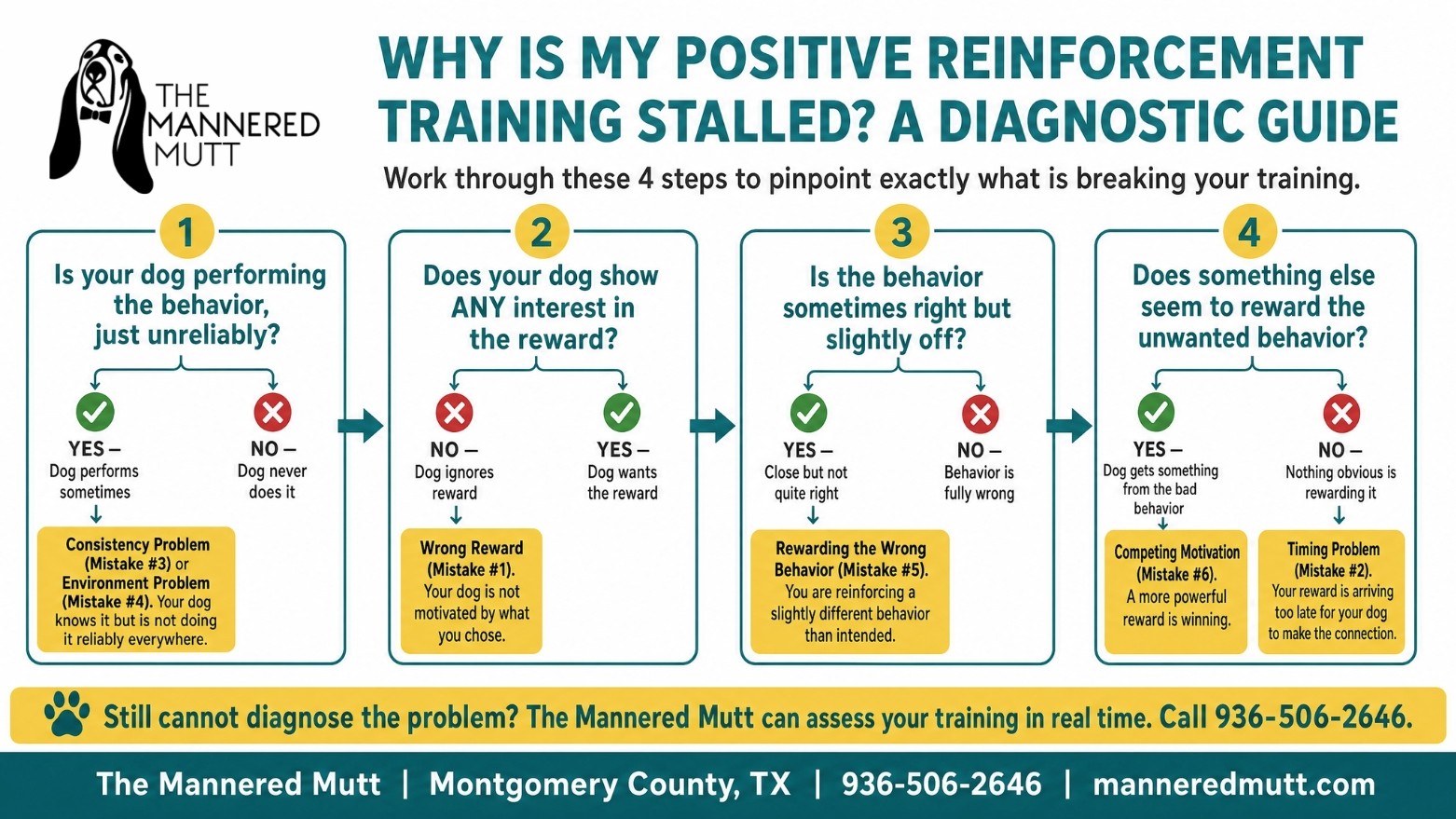
Understanding these mistakes helps you diagnose what’s broken in your training, not the method itself.
Mistake #1: The Reward Isn’t Actually Rewarding to Your Dog
What it looks like: You use treats or praise because “that’s what you’re supposed to do,” but your dog shows no increased motivation or desire to repeat the behavior.
Why it fails: Not all rewards are created equal. Your dog might be indifferent to the treat you chose. A dog who isn’t food-motivated won’t care about kibble. A dog who doesn’t bond closely with you might not find your praise meaningful. A dog who gets toys all day won’t be excited about one more toy.
The fix: Identify what YOUR dog actually wants. Observe what they’re naturally motivated toward. Does your dog get excited about specific treats but ignore others? Is your dog more motivated by play or toys than food? Does your dog value your attention and affection, or are they more independent? What does your dog do when they have free choice—play, eat, sniff, dig, chase? That’s your actual reward. Use that instead of what you think should work.
Mistake #2: Your Reward Timing is Slow or Inconsistent
What it looks like: You reward your dog “in the general ballpark” of the behavior. You mark good behavior but sometimes the reward comes a few seconds later. You miss some repetitions and reward others.
Why it fails: Dogs process timing in milliseconds. A 2-second delay between behavior and reward causes confusion about which behavior actually earned the reward. If your dog sits and you say “yes!” but then take 3 seconds to grab a treat from your pocket, your dog might have already stood up. The reward now marks standing, not sitting.
The fix: Reward within 0.5 seconds of the desired behavior. Ideally, have your rewards in hand BEFORE you start the training session. If using a clicker, click within half a second of the behavior, then deliver the reward immediately after. This precision is crucial for your dog to make the connection.
Mistake #3: You’re Not Rewarding Consistently Enough
What it looks like: You reward the behavior sometimes, but other times you ask for the same command and don’t reward (because you ran out of treats, or you were distracted, or you thought they “knew it well enough”).
Why it fails: Dogs learn through repetition and pattern recognition. They’re thinking: “When I sit, sometimes I get a reward and sometimes I don’t. It’s unpredictable. So why bother sitting every single time?” Inconsistent rewards make the behavior unreliable.
The fix: Reward EVERY correct response during the learning phase. Once the behavior is solid and your dog performs it reliably, you can gradually shift to variable ratio reinforcement (rewarding sometimes instead of always). But during learning, consistency is everything. This is non-negotiable for building reliable behaviors.
Mistake #4: You’re Training in the Wrong Environment (Wrong Context/Distraction Level)
What it looks like: Your dog sits perfectly during quiet training sessions in your living room. But at the dog park, the vet clinic, or a friend’s house, your dog completely ignores you.
Why it fails: Dogs don’t “generalize” learning across environments automatically. Your dog’s brain treats the living room as completely different from the dog park. What they learned in the quiet context hasn’t been practiced in the distracting context. This isn’t a reward problem—it’s a context problem.
The fix: Train in the location where you NEED the behavior to work. Start at low distraction, then gradually increase distraction level. If you want your dog to sit in the park, train sit at the park—starting at the quietest part, then practicing near busier areas as the behavior strengthens. Each new environment requires practice.
Mistake #5: You’re Rewarding the Wrong Behavior (and Didn’t Realize It)
What it looks like: You think you’re rewarding “sit” but your dog has learned something slightly different—like “sit for exactly 2 seconds then jump up” or “sit while staring at your treat hand” or “sit only when you’re holding the treat bag.”
Why it fails: Dogs learn exactly what you reward. If you reward your dog for sitting but then give the reward while they’re jumping (because you’re too slow), you’re accidentally training jump. If you always hold the treat at a specific height, your dog learns to sit in a position where they can see that hand, not a standard sit.
The fix: Be precise about what behavior you’re rewarding. Reward the exact version you want to see repeated. If your dog needs to sit and make eye contact, don’t reward a sit without eye contact. If your dog needs to sit and stay calm, don’t reward a sit with excitement. This precision matters more than most owners realize.
Mistake #6: You’re Not Addressing the Actual Motivation Behind the Unwanted Behavior
What it looks like: Your dog pulls on leash. You reward loose leash walking. But your dog still pulls because pulling works—they get to go toward something they want. The reward for walking loosely (a treat) is less powerful than the reward for pulling (reaching the other dog, the mailman, the squirrel).
Why it fails: Positive reinforcement training assumes you’re the most rewarding thing happening. But if your dog’s actual motivation (chasing the squirrel) is more rewarding than your treats, your rewards won’t win. You’re competing against more powerful rewards.
The fix: Remove access to the more powerful reward during training. If leash pulling is rewarded by reaching other dogs, train away from other dogs initially. If jumping on guests is reinforced by guest attention, manage the environment so guests can’t reward jumping. Once the behavior is solid on your rewards, then you can practice in the challenging context with ongoing reinforcement.
Here’s a quick reference table to help you identify which mistake you’re making:
How to Diagnose Which Mistake You’re Making